
STACKED LONG SHORT-TERM MEMORY AND HIDDEN MARKOV MODEL FOR SPEECH EMOTION RECOGNITION-A SYSTEMATIC REVIEW
DOI:
https://doi.org/10.33003/fjs-2026-1003-4565Keywords:
SER, LSTM, HMM, GMM, Hybrid modelAbstract
Speech Emotion Recognition (SER) plays a vital role in various real-world applications, from mental health diagnostics to human-computer interaction. This research examines the integration of Stacked Long Short-Term Memory (LSTM) networks and Hidden Markov Models (HMM) for SER, addressing the limitations of traditional models like Gaussian Mixture Models (GMM) and Support Vector Machines (SVM). While GMMs and SVMs offer decent performance, their inability to model temporal dynamics limits their accuracy in detecting complex emotions. The proposed hybrid model leverages LSTM’s strength in handling sequential data and HMM’s ability to model emotional transitions, making it highly suitable for real-world noisy environments. Preprocessing techniques such as MFCC and LPCC are applied to enhance feature extraction, and benchmark datasets like IEMOCAP and RAVDESS are used for evaluation. Finally, The Systematic review highlights the superior role of the hybrid model's performance on SER and sets the stage for a significant shift in future research in addressing bias and fairness in SER systems by combining LSTM and HMM as hybrid model. In recent studies, context-aware emotion recognition models are commonly evaluated using existing datasets such as IEMOCAP, MELD, DailyDialog, and SEMAINE, which provide conversational and multimodal emotional data. Features used often include acoustic features as MFCCs, spectrograms, prosodic features, linguistic features as BERT or transformer embeddings, and visual cues such as facial landmarks or video frames. Many models also incorporate contextual embeddings from transformers, graph attention networks, or sequential memory modules to capture speaker history and emotional shifts.
References
Abbaschian, B.J.; Sierra-Sosa, D.; Elmaghraby, A. (2021). Deep Learning Techniques for Speech Emotion Recognition, from Databases to Models. Sensors, 21(4), 1249. https://doi.org/10.3390/s21041249
Abbaschian, B.J.; Sierra-Sosa, D.; Elmaghraby, A. (2021). Deep Learning Techniques for Speech EmotionRecognition, from Databases to Models. Sensors, 21(4), 1249. https://doi.org/10.3390/s21041249
Ahmed, M. R., Islam, S., Islam, A. K. M. M., & Shatabda, S. (2023). An ensemble 1D-CNN-LSTM-GRU model with data augmentation for speech emotion recognition. IEEE.
Alhasan, S., Akinyemi, A. E., & Wisdom, D. D. (2020). A comparative performance study of machine learning algorithms for efficient data mining management of intrusion detection systems. International Journal of Engineering Applied Sciences and Technology, 5(6), 85-110. ISSN 2455-2143.
Amami, R. (2023). A robust voice pathology detection system based on the combined BiLSTM–CNN architecture. MENDEL Soft Computing Journal, 29 (2), 202–212. https://doi.org/10.13164/mendel.2023.k.202
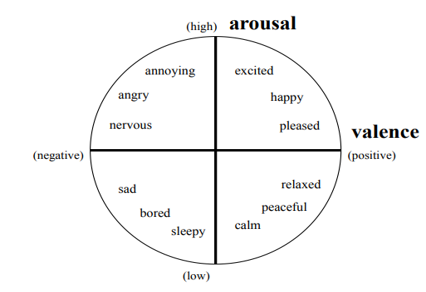
Bakker, I., Van der Voordt, T., Vink, P., & De Boon, J. (2014). Pleasure, arousal, dominance: Mehrabian and Russell revisited. Current Psychology, 33(3), 405-421.
Chamishka, S., Madhavi, I., Nawaratne, R., Alahakoon, D., De Silva, D., Chilamkurti, N., & Nanayakkara, V. (2022). A voice-based real-time emotion detection technique using recurrent neural network empowered feature modelling. Multimedia Tools and Applications, 81, 35173–35194. https://doi.org/10.1007/s11042-022-13363-4
Chen, C., & Zhang, P. (2024). TRNet: Two-level refinement network leveraging speech enhancement for noise robust speech emotion recognition. arXiv. https://arxiv.org/abs/2404.12979arXiv
Coto-Jiménez, M. (2021). Discriminative multi-stream post-filters based on deep learning for enhancing statistical parametric speech synthesis, in Biomimetics, MDPI, 6(1), 12. https://doi.org/10.3390/biomimetics6010012
Gendron, B., & Guibon, G. (2024). SEC: Context-aware metric learning for emotion recognition in conversation. Proceedings of the 14th Workshop on Computational Approaches to Subjectivity, Sentiment & Social Media Analysis (WASSA 2024), 8–18. https://aclanthology.org/2024.wassa-1.2
Haque, M. M., Islam, S., & Sadat, A. J. M. (2023). Capturing spectral and long-term contextual information for speech emotion recognition using deep learning techniques (B.Sc. thesis, Islamic University of Technology). Department of Computer Science and Engineering.
Harby, F., Alohali, M., Thaljaoui, A., & Talaat, A. S. (2024). Exploring Sequential Feature Selection in Deep Bi-LSTM Models for Speech Emotion Recognition. Computational and Mathematical Methods in Medicine, 78(2), 2716. https://doi.org/10.32604/cmc.2024.046623
Huang, J., Liu, B., & Tao, J. (2021). Learning long-term temporal contexts using skip RNN for continuous emotion recognition. Virtual Reality & Intelligent Hardware, 3(1), 55-64. https://doi.org/10.1016/j.vrih.2020.11.005.
Jalal, M. A., Loweimi, E., Moore, R. K., & Hain, T. (2019). Learning temporal clusters using capsule routing for speech emotion recognition. In Proceedings of Interspeech 2019 (pp. 1701-1705). ISCA. https://doi.org/10.21437/interspeech.2019-3068.
Le, D., Aldeneh, Z., & Mower Provost, E. (2017). Discretized continuous speech emotion recognition with multi-task deep recurrent neural network. Proceedings of the Interspeech Conference, 481-485. https://doi.org/10.21437/Interspeech.2017-1050.
Lee, J., & Tashev, I. (2015). High-level feature representation using recurrent neural network for speech emotion recognition. Proceedings of the Interspeech Conference.
Lim, W., Jang, D., & Lee, T. (2021). Speech emotion recognition using convolutional and recurrent neural networks. Audio and Acoustics Research Section, ETRI, Daejeon, Korea.
Lin, W.-C., & Busso, C. (2020). An efficient temporal modeling approach for speech emotion recognition by mapping varied duration sentences into a fixed number of chunks. In Proceedings of the MSP-Podcast dataset. Multimodal Signal Processing (MSP) Lab, The University of Texas at Dallas.
Lin, Z., Cruz, F., & Sandoval, E. B. (2024). Self-context-aware model (SCAM) for intelligent interaction. arXiv. https://arxiv.org/abs/2401.10946
Lin, Z., Cruz, F., & Sandoval, E. B. (2024). Self-context-aware model (SCAM) for intelligent interaction. arXiv. https://arxiv.org/abs/2401.10946
Mohammed, M. M., & Schuller, B. W. (2020). ConcealNet: An end-to-end neural network for packet loss concealment in deep speech emotion recognition. arXiv preprint arXiv:2005.07777.
Mu, Y., Hernández Gómez, L. A., Cano Montes, A., Alcaraz Martínez, C., Wang, X., & Gao, H. (2017). Speech emotion recognition using convolutional-recurrent neural networks with attention model. In Proceedings of the 2017 2nd International Conference on Computer Engineering, Information Science and Internet Technology (CII 2017) (ISBN: 978-1-60595-504-9).
Nakisa, B., Rastgoo, M. N., Rakotonirainy, A., Maire, F., & Chandran, V. (2018). Long short term memory hyperparameter optimization for a neural network based emotion recognition framework. IEEE Access, 6, 8670-8681. https://doi.org/10.1109/ACCESS.2018.2868361.
Nam, H.-J., & Park, H.-J. (2024). Speech emotion recognition under noisy environments with SNR down to –6 dB using multi-decoder Wave-U-Net. Applied Sciences, 14(12), 5227. https://doi.org/10.3390/app14125227
Patel, D., Amipara, S., Sanaria, M., Pareek, P., Jayaswal, R., & Patil, S. (2024). ASER: An exhaustive survey for speech recognition based on methods, datasets, challenges, and future scope. https://doi.org/10.18280/ria.380218.
Shahin, I., Hindawi, N., Bou Nassif, A., Alhudhaif, & Polat, K. (2023). Novel dual-channel long short-term memory compressed capsule networks for emotion recognition.
Sönmez, Y. Ü., & Varol, A. (2020). A speech emotion recognition model based on multi-level local binary and local ternary patterns. IEEE Access, 8, 187110-187121. https://doi.org/10.1109/ACCESS.2020.3031763.
Tanoko, Y., & Zahra, A. (2022). Multi-feature stacking order impact on speech emotion recognition performance. Bulletin of Electrical Engineering and Informatics, 11(6), 3272-3278. https://doi.org/10.11591/eei.v11i6.4287
Tzinis, E., & Potamianos, A. (2017). Segment-based speech emotion recognition using recurrent neural networks. In Proceedings of the IEEE Conference (pp. 1-8).2017 DOI: 10.1109/ACII.2017.8273599
Ullah, R., Asif, M., Shah, W. A., Anjam, F., Ullah, I., Khurshaid, T., Wuttisittikulkij, L., Shah, S., Ali, S. M., & Alibakhshikenari, M. (2023). Speech emotion recognition using convolution neural networks and multi-head convolutional transformers. Sensors, 23(13), 6212. https://doi.org/10.3390/s23136212.
Van Houdt, G., Mosquera, C., & Nápoles, G. (2020). A review on the long short-term memory model. Artificial Intelligence Review, 53(8), 5929-5955. https://doi.org/10.1007/s10462-020-09838-1.
Venkataramanan, K., & Rajamohan, H. R. (2019). Emotion recognition from speech. arXiv preprint arXiv:1912.10458.
Wang, L., Zhang, S., & Liu, Y. (2025). Graph attention model with contextual reasoning and emotion-shift awareness for conversational emotion recognition. Complex & Intelligent Systems, 1–14. https://doi.org/10.1007/s40747-025-01903-y
Wu, X., Cao, Y., Lu, H., Liu, S., Wang, D., Wu, Z., Liu, X., & Meng, H. (2021). Speech emotion recognition using sequential capsule networks. IEEE/ACM Transactions on Audio, Speech, and Language Processing, 29, 325–336. https://doi.org/10.1109/TASLP.2020.3039432.
Wu, X., Liu, S., Cao, Y., Li, X., Yu, J., Dai, D., Ma, X., Hu, S., Wu, Z., Liu, X., & Meng, H. (2019). Speech emotion recognition using capsule networks. Proceedings of the IEEE International Conference on Acoustics, Speech, and Signal Processing (ICASSP), 5386-4658. https://doi.org/10.1109/ICASSP.2019.8683652.
Zhang, H., Huang, H., & Han, H. (2021). A novel heterogeneous parallel convolution Bi-LSTM for speech emotion recognition. Applied Sciences, 11(21), 9897. https://doi.org/10.3390/app11219897
Zhang, H., Li, M., Chen, Y., & Wang, Q. (2024). CLEF: Counterfactual learning framework for debiasing context-aware emotion recognition. Emergent Mind, 1–12. https://www.emergentmind.com/papers/2403.05963
Zhang, C., Yu, J., & Chen, Z. (2021). Music Emotion Recognition Based on Combination of Multiple Features and Neural Network. 2021 IEEE 4th Advanced Information Management, Communicates, Electronic and Automation Control Conference (IMCEC). 1-6
Zhao, J., Mao, X., & Chen, L. (2019). Speech emotion recognition using deep 1D & 2D CNN LSTM networks. Biomedical Signal Processing and Control, 47, 312–323. https://doi.org/10.1016/j.bspc.2018.08.018.
Zhao, L., Xuan, J., Lou, J., Yu, Y., & Yang, W. (2025). Context-aware academic emotion dataset and benchmark (RAER). Proceedings of the IEEE/CVF International Conference on Computer Vision (ICCV).
Zheng, C., Wang, C., & Jia, N. (2019). An ensemble model for multi-level speech emotion recognition. Information, 10(12), 394. https://doi.org/10.3390/info10120394
Downloads
Published
Issue
Section
Categories
License
Copyright (c) 2026 Bature Hassan Joshua, Matthew Fagbola Temitayo, Bunmi Adewole Lawrence, Dauda Wisdom Daniel

This work is licensed under a Creative Commons Attribution 4.0 International License.

