
ROBERTaBART_X: A HYBRID TRANSFORMER MODEL FOR ENHANCING AUTOMATED CODE GENERATION
DOI:
https://doi.org/10.33003/fjs-2025-0911-3954Keywords:
Automated Code Generation, Transformer Models, RoBERTa, BART, Hybrid ArchitecturesAbstract
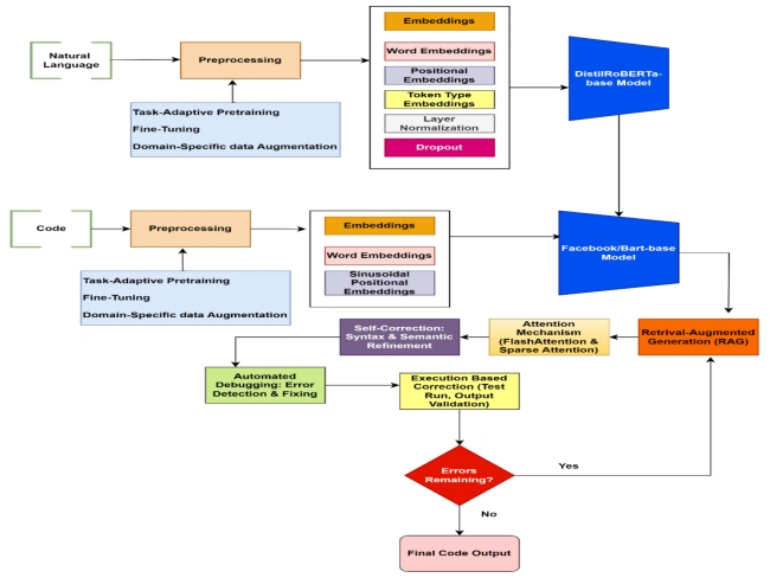
The use of automated code generation (ACG) has been a significant aspect of the software engineering process, enabling the production of code with greater speed and precision. However, many issues, such as the absence of long-term context, poor debugging, lack of domain adaptation, and functional inaccuracy, remain in the field of Automatic code generation. Even though its impact on Software engineering is apparently huge, these issues continue to exist. The model proposed herein, RoBERTaBART_X, is a hybrid transformer model based on RoBERTa and BART, supplemented by task-adaptive pretraining (TAPT), domain-specific data augmentation (DA), retrieval-augmented generation (RAG), FlashAttention, and sparse attention. The experiments were performed on standard datasets, including CoNaLa, Django, CodeSearchNet, and HumanEval, and were evaluated using BLEU, CodeBLEU, Exact Match Accuracy, Syntax Validity, and Execution Accuracy. The experiment results show that it outperforms all the baseline models of CodeBERT, CodeT5, RoBERTaMarian, and RoBERTaBART in semantic correctness, syntactic validity, execution success, CodeBLEU, and Pass@k. Most interestingly, RoBERTaBART_X achieves +6.1 BLEU and +6.6% Execution Accuracy on coNaLa, +4.8% Execution Accuracy on Django, and +3.2 % on CodeBLEU on codeSearchNet, demonstrating itself to be a strong competitor across diverse tasks. Given these findings, we recommend RoBERTaBART_X as the highest-performing model for generating resilient executable code to date. We believe that stacking strong encoders on top of autoregressive decoders and training them in a special way has the potential to push the already advanced automated code generation research even further.
References
Ahmad, W. U., Chakraborty, S., Ray, B., & Chang, K. W. (2021). Unified pre-training for program understanding and generation. Proceedings of the 2021 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, 2655–2668. https://doi.org/10.18653/v1/2021.naacl-main.211
Allamanis, M., Barr, E. T., Devanbu, P., & Sutton, C. (2018). A survey of machine learning for big code and naturalness. ACM Computing Surveys, 51(4), 81. https://doi.org/10.1145/3212695
Chen, M., Tworek, J., Jun, H., Yuan, Q., Pinto, H. P., Kaplan, J., & Zaremba, W. (2021). Evaluating large language models trained on code. arXiv preprint arXiv:2107.03374. https://arxiv.org/abs/2107.03374
Child, R., Gray, S., Radford, A., & Sutskever, I. (2019). Generating long sequences with sparse transformers. arXiv preprint arXiv:1904.10509. https://arxiv.org/abs/1904.10509
Dao, T., Fu, D. Y., Ermon, S., Rudra, A., & Ré, C. (2022). FlashAttention: Fast and memory-efficient exact attention with IO-awareness. Advances in Neural Information Processing Systems, 35, 16344–16359. https://arxiv.org/abs/2205.14135
Feng, Z., Guo, D., Tang, D., Duan, N., Feng, X., Gong, M., & Zhou, M. (2020). CodeBERT: A pre-trained model for programming and natural languages. Proceedings of the 2020 Conference on Empirical Methods in Natural Language Processing: Findings, 1536–1547. https://doi.org/10.18653/v1/2020.findings-emnlp.139
Lewis, M., Liu, Y., Goyal, N., Ghazvininejad, M., Mohamed, A., Levy, O., & Zettlemoyer, L. (2020). BART: Denoising sequence-to-sequence pre-training for natural language generation, translation, and comprehension. Proceedings of the 58th Annual Meeting of the Association for Computational Linguistics, 7871–7880. https://doi.org/10.18653/v1/2020.acl-main.703
Lewis, P., Perez, E., Piktus, A., Karpukhin, V., Goyal, N., Küttler, H., & Riedel, S. (2020). Retrieval-augmented generation for knowledge-intensive NLP tasks. Advances in Neural Information Processing Systems, 33, 9459–9474. https://arxiv.org/abs/2005.11401
Liu, I., Wang, Y., Zhang, Y., & Neubig, G. (2023). CodeT5+: Open code large language models for code understanding and generation. arXiv preprint arXiv:2305.07922. https://arxiv.org/abs/2305.07922
Liu, Y., Ott, M., Goyal, N., Du, J., Joshi, M., Chen, D., & Stoyanov, V. (2019). RoBERTa: A robustly optimized BERT pretraining approach. arXiv preprint arXiv:1907.11692. https://arxiv.org/abs/1907.11692
Papineni, K., Roukos, S., Ward, T., & Zhu, W. J. (2002). BLEU: A method for automatic evaluation of machine translation. Proceedings of the 40th Annual Meeting of the Association for Computational Linguistics, 311–318.https://doi.org/10.3115/1073083.1073135
Ren, S., Guo, D., Lu, S., Zhou, L., Ma, S., Zhou, J., & Li, H. (2020). CodeBLEU: A method for automatic evaluation of code synthesis. arXiv preprint arXiv:2009.10297. https://arxiv.org/abs/2009.10297
Wang, Y., Wang, W., Joty, S., & Hoi, S. C. (2021). CodeT5: Identifier-aware unified pre-trained encoder-decoder models for code understanding and generation. Proceedings of the 2021 Conference on Empirical Methods in Natural Language Processing, 8696–8708. https://doi.org/10.18653/v1/2021.emnlp-main.707
Downloads
Published
Issue
Section
Categories
License
Copyright (c) 2025 Adedayo Ajibade, Olaniyan Olatayo Moses

This work is licensed under a Creative Commons Attribution 4.0 International License.

